
Machine Learning on User Reviews
Background
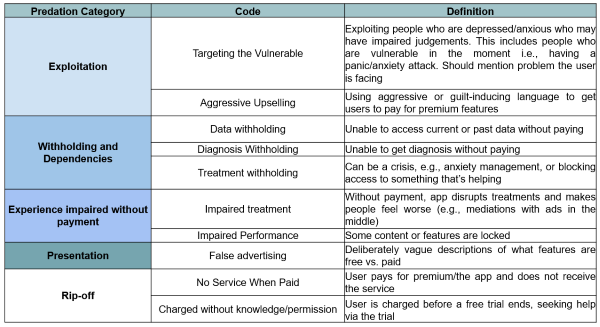
This project stemmed from a prior study, where we conducted a qualitative thematic analysis of user reviews left on mental health apps on the Google Play Store. Through the development of a codebook with five categories and nine subcodes (see Figure below), we analyzed and coded reviews describing predatory behaviors and features present in mobile apps for mental health. We initially noted that ~6% of reviews contained descriptions of predatory monetary practices implemented by app developers.
Using these coded reviews, we split our dataset of 10,000 reviews into training, tuning, and test sets and used various machine learning techniques (Naive Bayes, Support Vector Machines, and Decision Trees) to attempt to classify predatory reviews automatically. Initially, we focused on binary classification (yes/no if the reviews describes predation), and will move on to more granular classification using the subcodes in the future.
Project Goal: Can we use machine learning to identify predatory app behavior described in user reviews of mental health apps?
Project Year: 2021 - present
Algorithms Implemented
Using the Scikit learn Python library (a free machine learning library), we implemented the following supervised learning algorithms:
Naive Bayes applies Bayes’ Theorem, which predicts the probability of event occurrence based on prior knowledge. This algorithm assumes independence among predictive features and that words in a sentence are independent of each other. It has a high success rate in text classification.
Support Vector Machines are another widely used model for data classification and work well even with limited data (our set of 10k reviews is considered on the smaller side). This model plots each item and then finds the decision boundary to separate the two classes. Ideally, we want this separation to be as wide as possible for better accuracy.
Decisions Trees are the third predictive model we tested. Decision trees model decisions in a tree-like structure (hence the name). At decision points, conditions split the tree into branches for classification. The branches represent observations about a point or feature, and the leaves of the tree represent target values. The set of features are considered against each other to test the value of the decision split points.
Results
We implemented each of the three models and tested the following data features: unigrams, bigrams, trigrams, word counts, parts of speech, sentiment, review length, rating, feature selection, normalization, and binning. The results are shown in the below table. Naive Bayes produced the lowest scores on accuracy and precision, but it had the highest recall. This means Naive Bayes categorized reviews describing predatory behavior well. Better recall performance may be better overall for consumers as good recall catches predatory content well. Decision Trees showed high precision but low recall. Support Vector Machines were similar to Decision Trees but slightly better.
| Algorithm | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Naive Bayes | 89 | 65 | 92 | 76 |
| Support Vector Machines | 93 | 85 | 76 | 80 |
| Decision Trees | 91 | 77 | 75 | 76 |
Definitions
(see: here)
- Accuracy: The ratio of the number of correctly predicted observations to the total number of observations
- Precision: The ratio of correctly predicted positive observations to the total predicted positive observations. High precision = low false positive rate
- Recall: The ratio of correctly predicted positive observations to all observations in the actual class
- F-Score: The average of Precision + Recall